网站文件目录如/js/jquery-1.6.2+fix-9521.js
在某些IIS服务器中是不支持的,解决方法如下:
打开IIS,点击对应网站(或者当前服务器名,这样是设置整个服务器的);
找到 IIS >> 请求筛选(双击);
看右侧,找到“编辑功能设置”,点击进入;
勾选“允许双重转义”;
完成。
不明白的,加本人QQ
网站文件目录如/js/jquery-1.6.2+fix-9521.js
在某些IIS服务器中是不支持的,解决方法如下:
打开IIS,点击对应网站(或者当前服务器名,这样是设置整个服务器的);
找到 IIS >> 请求筛选(双击);
看右侧,找到“编辑功能设置”,点击进入;
勾选“允许双重转义”;
完成。
不明白的,加本人QQ
PDO(PHP Data Object) 是PHP 5 中加入的东西,是PHP 5新加入的一个重大功能,因为在PHP 5以前的php4/php3都是一堆的数据库扩展来跟各个数据库的连接和处理,什么 php_mysql.dll、php_pgsql.dll、php_mssql.dll、php_sqlite.dll等等。
1.PDO简介
PDO(PHP Data Object) 是PHP 5 中加入的东西,是PHP 5新加入的一个重大功能,因为在PHP 5以前的php4/php3都是一堆的数据库扩展来跟各个数据库的连接和处理,什么 php_mysql.dll、php_pgsql.dll、php_mssql.dll、php_sqlite.dll等等。
PHP6中也将默认使用PDO的方式连接,mysql扩展将被作为辅助
2.PDO配置
PHP.ini中,去掉”extension=php_pdo.dll”前面的”;”号,若要连接数据库,还需要去掉与PDO相关的数据库扩展前面的”;”号,然后重启Apache服务器即可。
extension=php_pdo.dll
extension=php_pdo_mysql.dll
extension=php_pdo_pgsql.dll
extension=php_pdo_sqlite.dll
extension=php_pdo_mssql.dll
extension=php_pdo_odbc.dll
extension=php_pdo_firebird.dll
……
3.PDO连接mysql数据库
new PDO(“mysql:host=localhost;dbname=db_demo”,”root”,”");
默认不是长连接,若要使用数据库长连接,需要在最后加如下参数:
new PDO(“mysql:host=localhost;dbname=db_demo”,”root”,”",”array(PDO::ATTR_PERSISTENT => true) “);
4.PDO常用方法及其应用
PDO::query() 主要是用于有记录结果返回的操作,特别是SELECT操作返回 PDOStatement 对象,失败返回false(当为 PDO::ERRMODE_SILENT,这也是默认的值)
PDO::exec() 主要是针对没有结果集合返回的操作,返回影响行数的(int),如INSERT(插入的行数)、 delete(删除的行数) 、UPDATE(和原数值不等才算)等操作, 失败返回false (当为 PDO::ERRMODE_SILENT,这也是默认的值)
PDO::prepare 执行所有sql,可以完全替代 query,exec的功能
PDO::lastInsertId() 返回上次插入操作,主键列类型是自增的最后的自增ID
PDOStatement::fetch() 是用来获取一条记录
PDOStatement::fetchAll() 是获取所有记录集到一个数组中
5.错误报告是针对执行的sql出错时
PDO::ERRMODE_SILENT(0) :默认 不提示任何错误 ,连接时无论如何都会提示,只有在执行后面的方法时才会起作用
PDO::ERRMODE_WARNING(1) : 警告
PDO::ERRMODE_EXCEPTION(2):异常(推荐使用) 用try catch捕获,也可以手动抛出异常 new PDOException($message, $code, $previous)
6.PDO操作MYSQL数据库实例
|
0 1 2 3 4 5 6 |
<?php $pdo = new PDO("mysql:host=localhost;dbname=db_demo","root",""); if($pdo -> exec("insert into db_demo(name,content) values('title','content')")){ echo "插入成功!"; echo $pdo -> lastinsertid(); } ?> |
|
0 1 2 3 4 5 6 |
<?php $pdo = new PDO("mysql:host=localhost;dbname=db_demo","root",""); $rs = $pdo -> query("select * from test"); while($row = $rs -> fetch()){ print_r($row); } ?> |
|
0 1 2 3 4 5 6 7 |
#exec用法 try { $sql = "insert into limove(`id`, `name`, `order`) values(null, 'sjk', 1),(null, 'sjk',2)"; $rows = $pdo->exec($sql); //影响的条数 2 $pdo->lastInsertId(); //最后插入的id,有多条时返回的是第一条的id } catch (Exception $e) { ee($pdo->errorInfo()); } |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#query方法同样也可以执行insert,delete 只是返回的结果集的格式 #同样 lastInsertId 照样也可以使用 $params = array ( PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES \'UTF8\'' , PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, ); $pdo = new PDO('mysql:host=127.0.0.1;dbname=test;port=3306', 'root', '',$params); $statement = "insert into card (id, json_str, f) values(null, 'ok', 2.3),(null, 'ok', 2.3)"; $flag = $pdo->query($statement); ee($flag); ee($pdo->lastInsertId()); PDOStatement Object ( [queryString] => insert into card (id, json_str, f) values(null, 'ok', 2.3),(null, 'ok', 2.3) ) |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 |
#query可以实现所有exec的功能 $params = array ( PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES \'UTF8\'' , PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, ); $pdo = new PDO('mysql:host=127.0.0.1;dbname=test;port=3306', 'root', '',$params); $statement = "insert into card. (id, json_str, f) values(null, 'ok', 2.3),(null, 'ok', 2.3)"; $statement = "select * from card"; $statement = "delete from card where id = 625"; $statement = "update card set f=5 where id = 624"; $stmt = $pdo->query($statement); ee($stmt->rowCount()); |
总结:
1、query和exec都可以执行所有的sql语句,只是返回值不同而已。
2、query可以实现所有exec的功能。
3、当把select语句应用到 exec 时,总是返回 0
注意:批量插入时,依次插入当遇到错误时后面的插入失败,但是前面的会插入成功。
预处理语句(prepare)示例,sql只编译一次,执行相同的sql效率会高。单个相比exec,query效率也高。
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#prepare 在不恰当的位置调用用法可能会出异常 $params = array ( PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES \'UTF8\'' , PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, ); $pdo = new PDO('mysql:host=127.0.0.1;dbname=test;port=3306', 'root', '',$params); // $sql = "insert into card (id, json_str, f) values(null, 'ok', 2.3),(null, 'ok', 2.3)"; // $sql = "select * from card"; $sql = "delete from card where id = 625"; // $sql = "update card set f=5 where id = 624"; // $sql = "show create table card"; // $sql = "desc card"; // $stmt = $pdo->query($sql); // ee($stmt->fetchAll()); // ee($stmt); $stmt = $pdo->prepare($sql); $stmt->execute(); ee($stmt->rowCount()); ee($stmt->fetch(pdo::FETCH_ASSOC)); Fatal error: Uncaught exception 'PDOException' with message 'SQLSTATE[HY000]: General error' in E:\wamp\www\test\song.php:27 Stack trace: #0 E:\wamp\www\test\song.php(27): PDOStatement->fetch(2) #1 {main} thrown in E:\wamp\www\test\song.php on line 27 |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
$dsn = "mysql:host=127.0.0.1;port=3306;dbname=test"; $opts = array(PDO::ATTR_AUTOCOMMIT=>0, PDO::ATTR_ERRMODE=>PDO::ERRMODE_EXCEPTION, PDO::ATTR_AUTOCOMMIT=>0); try { $pdo = new PDO($dsn, 'root', '', $opts); }catch(PDOException $e){ echo $e->getMessage(); } /* pdo中有两种占位符号 * * ? 参数 --- 索引数组, 按索引顺序使用 * 名子参数 ----关联数组, 按名称使用,和顺序无关 */ //准备好了一条语句,并入到服务器端,也已经编译过来了,就差为它分配数据过来 //同样适用于更新操作 $stmt=$pdo->prepare("insert into limove(`name`, `order`) values(:name,:order)"); //绑定参数,引用方式传递 $stmt->bindParam(":name", $name); $stmt->bindParam(":order", $order); // $stmt=$pdo->prepare("insert into limove(`name`, `order`) values(?, ?)"); //所有SQL都可执行 // //绑定参数,引用方式传递 // $stmt->bindParam(1, $name, PDO::PARAM_STR); #起始值为 1 // $stmt->bindParam(2, $order, PDO::PARAM_INT); #变量放到 bindParam 前后都可 $name="wwww"; $order = 1; if($stmt->execute()){ echo "执行成功"; echo "最后插入的ID:".$pdo->lastInsertId(); }else{ echo "执行失败!"; } |
还支持执行时绑定
|
0 1 2 3 4 5 6 7 8 |
#无序方式 $stmt=$pdo->prepare("insert into shops(name, price, num, desn) values(:name,:price, :num, :desn)"); $stmt->execute(array(":price"=>77, ":name"=>"kkk3", ":num"=>"453", ":desn"=>"aaaaaa3")); $stmt->execute(array(":price"=>77, ":name"=>"kkk3", ":num"=>"453", ":desn"=>"aaaaaa3")); #有序方式 $stmt=$pdo->prepare("insert into shops(name, price, num, desn) values(?, ?, ?, ?)"); //所有SQL都可执行 $stmt->execute(array("myname1", 11.2, 55, "very good")); $stmt->execute(array("myname1", 11.2, 55, "very good")); |
获取结果
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//获取结果 $stmt = $pdo->prepare("select * from limove where `order` = :order"); $stmt->execute(array(':order'=>8)); //设置获取的方式 $stmt->setFetchMode(PDO::FETCH_ASSOC); $data = array(); //方式1 //$data = $stmt->fetchAll(); //方式2 while($row = $stmt->fetch(PDO::FETCH_ASSOC)) { $data[] = $row; } ee($data); |
|
0 1 2 |
//bindColumn 把取出的值绑定到一个变量上 $stmt->bindColumn('name', $name); $stmt->bindColumn(2, $sex); # 还可以根据顺序绑定,可以混合使用 |
|
0 1 |
#所有的条数,select insert delete update $stmp->rowCount(); |
事务举例:
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
<?php try{ $pdo=new PDO("mysql:host=localhost;dbname=xsphpdb", "root", "123456", array(PDO::ATTR_AUTOCOMMIT=>0)); #一定要关闭自动提交 $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); #开启异常模式 }catch(PDOException $e){ echo "数据库连接失败:".$e->getMessage(); exit; } //执行SQL语句 exec() query() prepare() //一是有结果集的query(), 执行select语句 //exec()用来执行有影响行数的,update, delete insert, other //exec()返回的是影响的行数 /* * * 事务处理 * * 张三从李四那里买了一台 2000 元的电脑 * * 从张三帐号中扣出 2000元 * * 向李四账号中加入 2000元 * * 从商品表中减少一台电脑 * * MyIsAM InnoDB * */ try{ $pdo->beginTransaction(); $price=500; $sql="update zhanghao set price=price-{$price} where id=1"; $affected_rows=$pdo->exec($sql); if(!$affected_rows) throw new PDOException("张三转出失败"); $sql="update zhanghao set price=price+{$price} where id=3"; $affected_rows=$pdo->exec($sql); if(!$affected_rows) #发现问题手动抛出异常 throw new PDOException("向李四转入失败"); echo "交易成功!"; $pdo->commit(); }catch(PDOException $e){ echo $e->getMessage(); $pdo->rollback(); //只要捕获异常则回滚 } //不管执行成功还是失败最后都要在关闭自动提交 $pdo->setAttribute(PDO::ATTR_AUTOCOMMIT, 1); //设置错误报告模式 ERRMODE_SILENT ERRMODE_WARNING |
user contribute comments
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/** To avoid exposing your connection details should you fail to remember to catch any exception thrown by the PDO constructor you can use the following class to implicitly change the exception handler temporarily. */ Class SafePDO extends PDO { public static function exception_handler($e) { // Output the exception details die('Uncaught exception:'.$e->getMessage()); } public function __construct($dsn, $username='', $password='', $driver_options=array()) { // Temporarily change the PHP exception handler while we . . . set_exception_handler(array(__CLASS__, 'exception_handler')); // . . . create a PDO object parent::__construct($dsn, $username, $password, $driver_options); // Change the exception handler back to whatever it was before restore_exception_handler(); } } $dsn = 'mysql:host=127.0.0.1;dbname=tesst;port=3306'; $pdo = new SafePDO($dsn); |
|
0 1 2 3 4 5 6 |
#占位符的无效使用 $stmt = $dbh->prepare("SELECT * FROM REGISTRY where name LIKE '%?%'"); $stmt->execute(array($_GET['name'])); // 占位符必须被用在整个值的位置 $stmt = $dbh->prepare("SELECT * FROM REGISTRY where name LIKE ?"); $stmt->execute(array("%$_GET[name]%")); |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#开启两次失误会报错,下面解决了这个问题 class Database extends \\PDO { protected $transactionCounter = 0; function beginTransaction() { if(!$this->transactionCounter++) return parent::beginTransaction(); return $this->transactionCounter >= 0; } function commit() { if(!--$this->transactionCounter) return parent::commit(); return $this->transactionCounter >= 0; } function rollback() { if($this->transactionCounter >= 0) { $this->transactionCounter = 0; return parent::rollback(); } $this->transactionCounter = 0; return false; } //... } |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#模拟事务的嵌套使用,执行commit时会提交所有的事务 class Database extends PDO { protected $transactionCount = 0; public function beginTransaction() { if (!$this->transactionCounter++) { return parent::beginTransaction(); } $this->exec('SAVEPOINT trans'.$this->transactionCounter); return $this->transactionCounter >= 0; } public function commit() { if (!--$this->transactionCounter) { return parent::commit(); } return $this->transactionCounter >= 0; } public function rollback() { if (--$this->transactionCounter) { $this->exec('ROLLBACK TO trans'.$this->transactionCounter + 1); return true; } return parent::rollback(); } } |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/** * If you do not fetch all of the data in a result set before issuing your next call to PDO::query(), your call may fail. Call PDOStatement::closeCursor() to release the database resources associated with the PDOStatement object before issuing your next call to PDO::query(). */ $dsn = 'mysql:host=127.0.0.1;dbname=test;port=3306'; $params = array ( PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES \'UTF8\'' , PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, PDO::MYSQL_ATTR_USE_BUFFERED_QUERY =>0, //@warn ); $pdo = new PDO($dsn, 'root', '',$params); $sql_1 = "select * from card"; $stmt = $pdo->query($sql_1); $one = $stmt->fetch(); ee($one); // $stmt->closeCursor(); $sql_2 = "select * from card"; $stmt = $pdo->query($sql_2); $all = $stmt->fetchAll(); ee($all); |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/** 获取select的条数,需要公用一个数据库链接才行,会受到limit的影响 MySQL does not seem to return anything in rowCount for a select statement, but you can easily and efficiently get the row count as follows: */ class db extends PDO { public function last_row_count() { return $this->query("SELECT FOUND_ROWS()")->fetchColumn(); } } $myDb = new db('mysql:host=myhost;dbname=mydb', 'login', 'password' ); Then, after running your query: if ( $myDb->last_row_count() == 0 ) { echo "Do something!"; } |
更好的获取条数
|
0 1 2 3 4 |
$db = new PDO(DSN...); $db->setAttribute(array(PDO::MYSQL_USE_BUFFERED_QUERY=>TRUE)); $rs = $db->query('SELECT SQL_CALC_FOUND_ROWS * FROM table LIMIT 5,15'); $rs1 = $db->query('SELECT FOUND_ROWS()'); $rowCount = (int) $rs1->fetchColumn(); |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 |
/* 使用一个数组的值执行一条含有 IN 子句的预处理语句 */ $params = array(1, 21, 63, 171); /* 创建一个填充了和params相同数量占位符的字符串 */ $place_holders = implode(',', array_fill(0, count($params), '?')); /* 对于 $params 数组中的每个值,要预处理的语句包含足够的未命名占位符 。 语句被执行时, $params 数组中的值被绑定到预处理语句中的占位符。 这和使用 PDOStatement::bindParam() 不一样,因为它需要一个引用变量。 PDOStatement::execute() 仅作为通过值绑定的替代。 */ $sth = $dbh->prepare("SELECT id, name FROM contacts WHERE id IN ($place_holders)"); $sth->execute($params); |
|
0 1 2 3 4 5 6 7 8 9 10 11 |
/** $placeHolder */ data = ['a'=>'foo','b'=>'bar']; $keys = array_keys($data); $fields = '`'.implode('`, `',$keys).'`'; #here is my way $placeholder = substr(str_repeat('?,',count($keys),0,-1)); $pdo->prepare("INSERT INTO `baz`($fields) VALUES($placeholder)")->execute(array_values($data)); |
1、事务通常是通过把一批更改“积蓄”起来然后使之同时生效而实现的;这样做的好处是可以大大地提供这些更改的效率。
2、当脚本结束或连接即将被关闭时,如果尚有一个未完成的事务,那么 PDO 将自动回滚该事务。这种安全措施有助于在脚本意外终止时避免出现不一致的情况——如果没有显式地提交事务,那么假设是某个地方出错了,所以执行回滚来保证数据安全。
3、预处理语句 的好处
1、查询仅需解析(或预处理)一次,但可以用相同或不同的参数执行多次。 2、提供给预处理语句的参数不需要用引号括起来,驱动程序会自动处理。如果应用程序只使用预处理语句,可以确保不会发生S QL 注入。(然而,如果查询的其他部分是由未转义的输入来构建的,则仍存在 SQL 注入的风险)。
4、在事务中,lastInsertId 应该用在 commit之前,否则会得到 0
5、对于大多数数据库,PDOStatement::rowCount() 不能返回受一条 SELECT 语句影响的行数。替代的方法是,使用 PDO::query() 来发出一条和原打算中的SELECT语句有相同条件表达式的 SELECT COUNT(*) 语句,然后用 PDOStatement::fetchColumn() 来取得返回的行数。这样应用程序才能正确执行。
6、quote 增加引号
Ubuntu11.04默认的是UFW(ufw 即uncomplicated firewall的简称,不复杂的防火墙,繁琐部分的设置还是需要去到iptables)防火墙,已经支持界面操作了。在命令行运行ufw命令就可以看到提示的一系列可进行的操作
最简单的一个操作:
sudo ufw status(如果你是root,则去掉sudo,ufw status)可检查防火墙的状态,我的返回的是:inactive(默认为不活动)。
sudo ufw version防火墙版本:
ufw 0.29-4ubuntu1
Copyright 2008-2009 Canonical Ltd.
ubuntu 系统默认已安装ufw.
1.安装
sudo apt-get install ufw
2.启用
sudo ufw enable
sudo ufw default deny
运行以上两条命令后,开启了防火墙,并在系统启动时自动开启。关闭所有外部对本机的访问,但本机访问外部正常。
3.开启/禁用
sudo ufw allow|deny [service]
打开或关闭某个端口,例如:
sudo ufw allow smtp 允许所有的外部IP访问本机的25/tcp (smtp)端口
sudo ufw allow 22/tcp 允许所有的外部IP访问本机的22/tcp (ssh)端口
这个很重要,ssh远程登录用于SecureCRT等软件建议开启。或者不要开防火墙。
sudo ufw allow 53 允许外部访问53端口(tcp/udp)
sudo ufw allow from 192.168.1.100 允许此IP访问所有的本机端口
sudo ufw allow proto udp 192.168.0.1 port 53 to 192.168.0.2 port 53
sudo ufw deny smtp 禁止外部访问smtp服务
sudo ufw delete allow smtp 删除上面建立的某条规则
4.查看防火墙状态
sudo ufw status
一般用户,只需如下设置:
sudo apt-get install ufw
sudo ufw enable
sudo ufw default deny
以上三条命令已经足够安全了,如果你需要开放某些服务,再使用sudo ufw allow开启。
开启/关闭防火墙 (默认设置是’disable’)
sudo ufw enable|disable
转换日志状态
sudo ufw logging on|off
设置默认策略 (比如 “mostly open” vs “mostly closed”)
sudo ufw default allow|deny
许 可或者屏蔽端口 (可以在“status” 中查看到服务列表)。可以用“协议:端口”的方式指定一个存在于/etc/services中的服务名称,也可以通过包的meta-data。 ‘allow’ 参数将把条目加入 /etc/ufw/maps ,而 ‘deny’ 则相反。基本语法如下:
sudo ufw allow|deny [service]
显示防火墙和端口的侦听状态,参见 /var/lib/ufw/maps。括号中的数字将不会被显示出来。
sudo ufw status
UFW 使用范例:
允许 53 端口
$ sudo ufw allow 53
禁用 53 端口
$ sudo ufw delete allow 53
允许 80 端口
$ sudo ufw allow 80/tcp
禁用 80 端口
$ sudo ufw delete allow 80/tcp
允许 smtp 端口
$ sudo ufw allow smtp
删除 smtp 端口的许可
$ sudo ufw delete allow smtp
允许某特定 IP
$ sudo ufw allow from 192.168.254.254
删除上面的规则
$ sudo ufw delete allow from 192.168.254.254
linux 2.4内核以后提供了一个非常优秀的防火墙工具:netfilter/iptables,他免费且功能强大,可以对流入、流出的信息进行细化控制,它可以 实现防火墙、NAT(网络地址翻译)和数据包的分割等功能。netfilter工作在内核内部,而iptables则是让用户定义规则集的表结构。
但是iptables的规则稍微有些“复杂”,因此ubuntu提供了ufw这个设定工具,以简化iptables的某些设定,其后台仍然是 iptables。ufw 即uncomplicated firewall的简称,一些复杂的设定还是要去iptables。
ufw相关的文件和文件夹有:
/etc /ufw/:里面是一些ufw的环境设定文件,如 before.rules、after.rules、sysctl.conf、ufw.conf,及 for ip6 的 before6.rule 及 after6.rules。这些文件一般按照默认的设置进行就ok。
若开启ufw之 后,/etc/ufw/sysctl.conf会覆盖默认的/etc/sysctl.conf文件,若你原来的/etc/sysctl.conf做了修 改,启动ufw后,若/etc/ufw/sysctl.conf中有新赋值,则会覆盖/etc/sysctl.conf的,否则还以/etc /sysctl.conf为准。当然你可以通过修改/etc/default/ufw中的“IPT_SYSCTL=”条目来设置使用哪个 sysctrl.conf.
/var/lib/ufw/user.rules 这个文件中是我们设置的一些防火墙规则,打开大概就能看明白,有时我们可以直接修改这个文件,不用使用命令来设定。修改后记得ufw reload重启ufw使得新规则生效。
下面是ufw命令行的一些示例:
ufw enable/disable:打开/关闭ufw
ufw status:查看已经定义的ufw规则
ufw default allow/deny:外来访问默认允许/拒绝
ufw allow/deny 20:允许/拒绝 访问20端口,20后可跟/tcp或/udp,表示tcp或udp封包。
ufw allow/deny servicename:ufw从/etc/services中找到对应service的端口,进行过滤。
ufw allow proto tcp from 10.0.1.0/10 to 本机ip port 25:允许自10.0.1.0/10的tcp封包访问本机的25端口。
ufw delete allow/deny 20:删除以前定义的”允许/拒绝访问20端口”的规则
网站用着百度的免费版云加速,刚才发文章可能是有敏感字符,被禁。
那么就进云加速增加一条白名单吧,结果发现增加白名单要收费了。
因为没钱,所以只好选择关闭“Web应用防火墙”,发布完文章,点击查看,“秒进”。
就我这个站来讲,关闭云加速后,提速有200%左右。
原来之前网站这么慢的原因在这里啊,真是太愁人了。
我不是污蔑,这是事实,当然优点也是有的,优点大于缺点,继续使用。
最近想好好研究下Linux,感觉挺好,学习中…
查找目录:find /(查找范围) -name ‘查找关键字’ -type d
查找文件:find /(查找范围) -name 查找关键字 -print
如果需要更进一步的了解,可以参看Linux的命令详解。
这里摘抄如下:
·find path -option [ -print ] [ -exec -ok command ] {} /;
#-print 将查找到的文件输出到标准输出
#-exec command {} /; —–将查到的文件执行command操作,{} 和 /;之间有空格
#-ok 和-exec相同,只不过在操作前要询用户
====================================================
-name filename #查找名为filename的文件
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 #查更改时间比f1新但比f2旧的文件
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-depth #使查找在进入子目录前先行查找完本目录
-fstype #查更改时间比f1新但比f2旧的文件
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-depth #使查找在进入子目录前先行查找完本目录
-fstype #查位于某一类型文件系统中的文件,这些文件系统类型通常可 在/etc/fstab中找到
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-cpio #查位于某一类型文件系统中的文件,这些文件系统类型通常可 在/etc/fstab中找到
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-cpio #对匹配的文件使用cpio命令,将他们备份到磁带设备中
-prune #忽略某个目录
====================================================
$find ~ -name “*.txt” -print #在$HOME中查.txt文件并显示
$find . -name “*.txt” -print
$find . -name “[A-Z]*” -pri26nbsp; #对匹配的文件使用cpio命令,将他们备份到磁带设备中
-prune #忽略某个目录
=====================================================
$find ~ -name “*.txt” -print #在$HOME中查.txt文件并显示
$find . -name “*.txt” -print
$find . -name “[A-Z]*” -print #查以大写字母开头的文件
$find /etc -name “host*” -print #查以host开头的文件
$find . -name “[a-z][a-z][0--9][0--9].txt” -print #查以两个小写字母和两个数字开头的txt文件
$find . -perm 755 -print
$find . -perm -007 -exec ls -l {} /; #查所有用户都可读写执行的文件同-perm 777
$find . -type d -print
$find . ! -type d -print
$find . -type l -print
$find . -size +1000000c -print #查长度大于1Mb的文件
$find . -size 100c -print # 查长度为100c的文件
$find . -size +10 -print #查长度超过期作废10块的文件(1块=512字节)
$cd /
$find etc home apps -depth -print | cpio -ivcdC65536 -o /dev/rmt0
$find /etc -name “passwd*” -exec grep “cnscn” {} /; #看是否存在cnscn用户
$find . -name “yao*” | xargs file
$find . -name “yao*” | xargs echo “” > /tmp/core.log
$find . -name “yao*” | xargs chmod o-w
======================================================
find -name april* 在当前目录下查找以april开始的文件
find -name april* fprint file 在当前目录下查找以april开始的文件,并把结果输出到file中
find -name ap* -o -name may* 查找以ap或may开头的文件
find /mnt -name tom.txt -ftype vfat 在/mnt下查找名称为tom.txt且文件系统类型为vfat的文件
find /mnt -name t.txt ! -ftype vfat 在/mnt下查找名称为tom.txt且文件系统类型不为vfat的文件
find /tmp -name wa* -type l 在/tmp下查找名为wa开头且类型为符号链接的文件
find /home -mtime -2 在/home下查最近两天内改动过的文件
find /home -atime -1 查1天之内被存取过的文件
find /home -mmin +60 在/home下查60分钟前改动过的文件
find /home -amin +30 查最近30分钟前被存取过的文件
find /home -newer tmp.txt 在/home下查更新时间比tmp.txt近的文件或目录
find /home -anewer tmp.txt 在/home下查存取时间比tmp.txt近的文件或目录
find /home -used -2 列出文件或目录被改动过之后,在2日内被存取过的文件或目录
find /home -user cnscn 列出/home目录内属于用户cnscn的文件或目录
find /home -uid +501 列出/home目录内用户的识别码大于501的文件或目录
find /home -group cnscn 列出/home内组为cnscn的文件或目录
find /home -gid 501 列出/home内组id为501的文件或目录
find /home -nouser 列出/home内不属于本地用户的文件或目录
find /home -nogroup 列出/home内不属于本地组的文件或目录
find /home -name tmp.txt -maxdepth 4 列出/home内的tmp.txt 查时深度最多为3层
find /home -name tmp.txt -mindepth 3 从第2层开始查
find /home -empty 查找大小为0的文件或空目录
find /home -size +512k 查大于512k的文件
find /home -size -512k 查小于512k的文件
find /home -links +2 查硬连接数大于2的文件或目录
find /home -perm 0700 查权限为700的文件或目录
find /tmp -name tmp.txt -exec cat {} /;
find /tmp -name tmp.txt -ok rm {} /;
find / -amin -10 # 查找在系统中最后10分钟访问的文件
find / -atime -2 # 查找在系统中最后48小时访问的文件
find / -empty # 查找在系统中为空的文件或者文件夹
find / -group cat # 查找在系统中属于 groupcat的文件
find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件
find / -mtime -1 #查找在系统中最后24小时里修改过的文件
find / -nouser #查找在系统中属于作废用户的文件
find / -user fred #查找在系统中属于FRED这个用户的文件
查当前目录下的所有普通文件
——————————————————————————–
# find . -type f -exec ls -l {} /;
-rw-r–r– 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r–r– 1 root root 12959 2003-02-25 ./conf/magic
-rw-r–r– 1 root root 180 2003-02-25 ./conf.d/README
查当前目录下的所有普通文件,并在- e x e c选项中使用ls -l命令将它们列出
=================================================
在/ l o g s目录中查找更改时间在5日以前的文件并删除它们:
$ find logs -type f -mtime +5 -exec -ok rm {} /;
=================================================
查询当天修改过的文件
[root@book class]# find ./ -mtime -1 -type f -exec ls -l {} /;
=================================================
查询文件并询问是否要显示
[root@book class]# find ./ -mtime -1 -type f -ok ls -l {} /;
< ls … ./classDB.inc.PHP > ? y
-rw-r–r– 1 cnscn cnscn 13709 1月 12 12:22 ./classDB.inc.php
[root@book class]# find ./ -mtime -1 -type f -ok ls -l {} /;
< ls … ./classDB.inc.php > ? n
[root@book class]#
=================================================
查询并交给awk去处理
[root@book class]# who | awk ‘{print $1″/t”$2}’
cnscn pts/0
=================================================
awk—grep—sed
[root@book class]# df -k | awk ‘{print $1}’ | grep -v ‘none’ | sed s”///dev////g”
文件系统
sda2
sda1
[root@book class]# df -k | awk ‘{print $1}’ | grep -v ‘none’
文件系统
/dev/sda2
/dev/sda1
1)在/tmp中查找所有的*.h,并在这些文件中查找“SYSCALL_VECTOR”,最后打印出所有包含”SYSCALL_VECTOR”的文件名
A) find /tmp -name “*.h” | xargs -n50 grep SYSCALL_VECTOR
B) grep SYSCALL_VECTOR /tmp/*.h | cut -d’:’ -f1| uniq > filename
C) find /tmp -name “*.h” -exec grep “SYSCALL_VECTOR” {} /; -print
2)find / -name filename -exec rm -rf {} /;
find / -name filename -ok rm -rf {} /;
3)比如要查找磁盘中大于3M的文件:
find . -size +3000k -exec ls -ld {} ;
4)将find出来的东西拷到另一个地方
find *.c -exec cp ‘{}’ /tmp ‘;’
如果有特殊文件,可以用cpio,也可以用这样的语法:
find dir -name filename -print | cpio -pdv newdir
6)查找2004-11-30 16:36:37时更改过的文件
# A=find ./ -name "*php" | ls -l –full-time $A 2>/dev/null | grep “2004-11-30 16:36:37″
Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有为数不多的几个发行版尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
使用Systemctl管理Linux服务
使用Systemctl管理Linux服务
本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
Systemd初体验和Systemctl基础
1. 首先检查你的系统中是否安装有systemd并确定当前安装的版本
|
0 1 2 |
# systemctl --version systemd 215 +PAM +AUDIT +SELINUX +IMA +SYSVINIT +LIBCRYPTSETUP +GCRYPT +ACL +XZ -SECCOMP -APPARMOR |
上例中很清楚地表明,我们安装了215版本的systemd。
2. 检查systemd和systemctl的二进制文件和库文件的安装位置
|
0 1 2 3 |
# whereis systemd systemd: /usr/lib/systemd /etc/systemd /usr/share/systemd /usr/share/man/man1/systemd.1.gz # whereis systemctl systemctl: /usr/bin/systemctl /usr/share/man/man1/systemctl.1.gz |
3. 检查systemd是否运行
|
0 1 2 3 4 5 |
# ps -eaf | grep [s]ystemd root 1 0 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd --switched-root --system --deserialize 23 root 444 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-journald root 469 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-udevd root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation |
注意:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(即 -eaf)。
也请注意上例中后随的方括号和例子中剩余部分。方括号表达式是grep的字符类表达式的一部分。
4. 分析systemd启动进程
|
0 1 |
# systemd-analyze Startup finished in 487ms (kernel) + 2.776s (initrd) + 20.229s (userspace) = 23.493s |
5. 分析启动时各个进程花费的时间
|
0 1 2 3 4 5 6 7 8 9 10 11 |
# systemd-analyze blame 8.565s mariadb.service 7.991s webmin.service 6.095s postfix.service 4.311s httpd.service 3.926s firewalld.service 3.780s kdump.service 3.238s tuned.service 1.712s network.service 1.394s lvm2-monitor.service 1.126s systemd-logind.service .... |
6. 分析启动时的关键链
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# systemd-analyze critical-chain The time after the unit is active or started is printed after the "@" character. The time the unit takes to start is printed after the "+" character. multi-user.target @20.222s └─mariadb.service @11.657s +8.565s └─network.target @11.168s └─network.service @9.456s +1.712s └─NetworkManager.service @8.858s +596ms └─firewalld.service @4.931s +3.926s └─basic.target @4.916s └─sockets.target @4.916s └─dbus.socket @4.916s └─sysinit.target @4.905s └─systemd-update-utmp.service @4.864s +39ms └─auditd.service @4.563s +301ms └─systemd-tmpfiles-setup.service @4.485s +69ms └─rhel-import-state.service @4.342s +142ms └─local-fs.target @4.324s └─boot.mount @4.286s +31ms └─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d19608096 └─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4 |
重要:Systemctl接受服务(.service),挂载点(.mount),套接口(.socket)和设备(.device)作为单元。
7. 列出所有可用单元
|
0 1 2 3 4 5 6 7 8 9 10 11 |
# systemctl list-unit-files UNIT FILE STATE proc-sys-fs-binfmt_misc.automount static dev-hugepages.mount static dev-mqueue.mount static proc-sys-fs-binfmt_misc.mount static sys-fs-fuse-connections.mount static sys-kernel-config.mount static sys-kernel-debug.mount static tmp.mount disabled brandbot.path disabled ..... |
8. 列出所有运行中单元
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# systemctl list-units UNIT LOAD ACTIVE SUB DESCRIPTION proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary Executable File Formats File Syste sys-devices-pc...0-1:0:0:0-block-sr0.device loaded active plugged VBOX_CD-ROM sys-devices-pc...:00:03.0-net-enp0s3.device loaded active plugged PRO/1000 MT Desktop Adapter sys-devices-pc...00:05.0-sound-card0.device loaded active plugged 82801AA AC'97 Audio Controller sys-devices-pc...:0:0-block-sda-sda1.device loaded active plugged VBOX_HARDDISK sys-devices-pc...:0:0-block-sda-sda2.device loaded active plugged LVM PV Qzyo3l-qYaL-uRUa-Cjuk-pljo-qKtX-VgBQ8 sys-devices-pc...0-2:0:0:0-block-sda.device loaded active plugged VBOX_HARDDISK sys-devices-pl...erial8250-tty-ttyS0.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS0 sys-devices-pl...erial8250-tty-ttyS1.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS1 sys-devices-pl...erial8250-tty-ttyS2.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS2 sys-devices-pl...erial8250-tty-ttyS3.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS3 sys-devices-virtual-block-dm\x2d0.device loaded active plugged /sys/devices/virtual/block/dm-0 sys-devices-virtual-block-dm\x2d1.device loaded active plugged /sys/devices/virtual/block/dm-1 sys-module-configfs.device loaded active plugged /sys/module/configfs ... |
9. 列出所有失败单元
|
0 1 2 3 4 5 6 7 |
# systemctl --failed UNIT LOAD ACTIVE SUB DESCRIPTION kdump.service loaded failed failed Crash recovery kernel arming LOAD = Reflects whether the unit definition was properly loaded. ACTIVE = The high-level unit activation state, i.e. generalization of SUB. SUB = The low-level unit activation state, values depend on unit type. 1 loaded units listed. Pass --all to see loaded but inactive units, too. To show all installed unit files use 'systemctl list-unit-files'. |
10. 检查某个单元(如 cron.service)是否启用
|
0 1 |
# systemctl is-enabled crond.service enabled |
11. 检查某个单元或服务是否运行
|
0 1 2 3 4 5 6 7 8 |
# systemctl status firewalld.service firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled) Active: active (running) since Tue 2015-04-28 16:27:55 IST; 34min ago Main PID: 549 (firewalld) CGroup: /system.slice/firewalld.service └─549 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid Apr 28 16:27:51 tecmint systemd[1]: Starting firewalld - dynamic firewall daemon... Apr 28 16:27:55 tecmint systemd[1]: Started firewalld - dynamic firewall daemon. |
使用Systemctl控制并管理服务
12. 列出所有服务(包括启用的和禁用的)
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 |
# systemctl list-unit-files --type=service UNIT FILE STATE arp-ethers.service disabled auditd.service enabled autovt@.service disabled blk-availability.service disabled brandbot.service static collectd.service disabled console-getty.service disabled console-shell.service disabled cpupower.service disabled crond.service enabled dbus-org.fedoraproject.FirewallD1.service enabled .... |
13. Linux中如何启动、重启、停止、重载服务以及检查服务(如 httpd.service)状态
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# systemctl start httpd.service # systemctl restart httpd.service # systemctl stop httpd.service # systemctl reload httpd.service # systemctl status httpd.service httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled) Active: active (running) since Tue 2015-04-28 17:21:30 IST; 6s ago Process: 2876 ExecStop=/bin/kill -WINCH ${MAINPID} (code=exited, status=0/SUCCESS) Main PID: 2881 (httpd) Status: "Processing requests..." CGroup: /system.slice/httpd.service ├─2881 /usr/sbin/httpd -DFOREGROUND ├─2884 /usr/sbin/httpd -DFOREGROUND ├─2885 /usr/sbin/httpd -DFOREGROUND ├─2886 /usr/sbin/httpd -DFOREGROUND ├─2887 /usr/sbin/httpd -DFOREGROUND └─2888 /usr/sbin/httpd -DFOREGROUND Apr 28 17:21:30 tecmint systemd[1]: Starting The Apache HTTP Server... Apr 28 17:21:30 tecmint httpd[2881]: AH00558: httpd: Could not reliably determine the server's fully q...ssage Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server. Hint: Some lines were ellipsized, use -l to show in full. |
注意:当我们使用systemctl的start,restart,stop和reload命令时,我们不会从终端获取到任何输出内容,只有status命令可以打印输出。
14. 如何激活服务并在启动时启用或禁用服务(即系统启动时自动启动服务)
|
0 1 2 |
# systemctl is-active httpd.service # systemctl enable httpd.service # systemctl disable httpd.service |
15. 如何屏蔽(让它不能启动)或显示服务(如 httpd.service)
|
0 1 2 3 |
# systemctl mask httpd.service ln -s '/dev/null' '/etc/systemd/system/httpd.service' # systemctl unmask httpd.service rm '/etc/systemd/system/httpd.service' |
16. 使用systemctl命令杀死服务
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# systemctl kill httpd # systemctl status httpd httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled) Active: failed (Result: exit-code) since Tue 2015-04-28 18:01:42 IST; 28min ago Main PID: 2881 (code=exited, status=0/SUCCESS) Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec" Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled. Apr 28 18:01:42 tecmint systemd[1]: httpd.service: control process exited, code=exited status=226 Apr 28 18:01:42 tecmint systemd[1]: Unit httpd.service entered failed state. Hint: Some lines were ellipsized, use -l to show in full. |
使用Systemctl控制并管理挂载点
17. 列出所有系统挂载点
|
0 1 2 3 4 5 6 7 8 |
# systemctl list-unit-files --type=mount UNIT FILE STATE dev-hugepages.mount static dev-mqueue.mount static proc-sys-fs-binfmt_misc.mount static sys-fs-fuse-connections.mount static sys-kernel-config.mount static sys-kernel-debug.mount static tmp.mount disabled |
18. 挂载、卸载、重新挂载、重载系统挂载点并检查系统中挂载点状态
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# systemctl start tmp.mount # systemctl stop tmp.mount # systemctl restart tmp.mount # systemctl reload tmp.mount # systemctl status tmp.mount tmp.mount - Temporary Directory Loaded: loaded (/usr/lib/systemd/system/tmp.mount; disabled) Active: active (mounted) since Tue 2015-04-28 17:46:06 IST; 2min 48s ago Where: /tmp What: tmpfs Docs: man:hier(7) http://www.freedesktop.org/wiki/Software/systemd/APIFileSystems Process: 3908 ExecMount=/bin/mount tmpfs /tmp -t tmpfs -o mode=1777,strictatime (code=exited, status=0/SUCCESS) Apr 28 17:46:06 tecmint systemd[1]: Mounting Temporary Directory... Apr 28 17:46:06 tecmint systemd[1]: tmp.mount: Directory /tmp to mount over is not empty, mounting anyway. Apr 28 17:46:06 tecmint systemd[1]: Mounted Temporary Directory. |
19. 在启动时激活、启用或禁用挂载点(系统启动时自动挂载)
|
0 1 2 |
# systemctl is-active tmp.mount # systemctl enable tmp.mount # systemctl disable tmp.mount |
20. 在Linux中屏蔽(让它不能启用)或可见挂载点
|
0 1 2 3 |
# systemctl mask tmp.mount ln -s '/dev/null' '/etc/systemd/system/tmp.mount' # systemctl unmask tmp.mount rm '/etc/systemd/system/tmp.mount' |
使用Systemctl控制并管理套接口
21. 列出所有可用系统套接口
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 |
# systemctl list-unit-files --type=socket UNIT FILE STATE dbus.socket static dm-event.socket enabled lvm2-lvmetad.socket enabled rsyncd.socket disabled sshd.socket disabled syslog.socket static systemd-initctl.socket static systemd-journald.socket static systemd-shutdownd.socket static systemd-udevd-control.socket static systemd-udevd-kernel.socket static 11 unit files listed. |
22. 在Linux中启动、重启、停止、重载套接口并检查其状态
|
0 1 2 3 4 5 6 7 8 9 10 |
# systemctl start cups.socket # systemctl restart cups.socket # systemctl stop cups.socket # systemctl reload cups.socket # systemctl status cups.socket cups.socket - CUPS Printing Service Sockets Loaded: loaded (/usr/lib/systemd/system/cups.socket; enabled) Active: active (listening) since Tue 2015-04-28 18:10:59 IST; 8s ago Listen: /var/run/cups/cups.sock (Stream) Apr 28 18:10:59 tecmint systemd[1]: Starting CUPS Printing Service Sockets. Apr 28 18:10:59 tecmint systemd[1]: Listening on CUPS Printing Service Sockets. |
23. 在启动时激活套接口,并启用或禁用它(系统启动时自启动)
|
0 1 2 |
# systemctl is-active cups.socket # systemctl enable cups.socket # systemctl disable cups.socket |
24. 屏蔽(使它不能启动)或显示套接口
|
0 1 2 3 |
# systemctl mask cups.socket ln -s '/dev/null' '/etc/systemd/system/cups.socket' # systemctl unmask cups.socket rm '/etc/systemd/system/cups.socket' |
服务的CPU利用率(分配额)
25. 获取当前某个服务的CPU分配额(如httpd)
|
0 1 |
# systemctl show -p CPUShares httpd.service CPUShares=1024 |
注意:各个服务的默认CPU分配份额=1024,你可以增加/减少某个进程的CPU分配份额。
26. 将某个服务(httpd.service)的CPU分配份额限制为2000 CPUShares/
|
0 1 2 |
# systemctl set-property httpd.service CPUShares=2000 # systemctl show -p CPUShares httpd.service CPUShares=2000 |
注意:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(如 httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
0 1 2 |
# vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf [Service] CPUShares=2000 |
27. 检查某个服务的所有配置细节
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# systemctl show httpd Id=httpd.service Names=httpd.service Requires=basic.target Wants=system.slice WantedBy=multi-user.target Conflicts=shutdown.target Before=shutdown.target multi-user.target After=network.target remote-fs.target nss-lookup.target systemd-journald.socket basic.target system.slice Description=The Apache HTTP Server LoadState=loaded ActiveState=active SubState=running FragmentPath=/usr/lib/systemd/system/httpd.service .... |
28. 分析某个服务(httpd)的关键链
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# systemd-analyze critical-chain httpd.service The time after the unit is active or started is printed after the "@" character. The time the unit takes to start is printed after the "+" character. httpd.service +142ms └─network.target @11.168s └─network.service @9.456s +1.712s └─NetworkManager.service @8.858s +596ms └─firewalld.service @4.931s +3.926s └─basic.target @4.916s └─sockets.target @4.916s └─dbus.socket @4.916s └─sysinit.target @4.905s └─systemd-update-utmp.service @4.864s +39ms └─auditd.service @4.563s +301ms └─systemd-tmpfiles-setup.service @4.485s +69ms └─rhel-import-state.service @4.342s +142ms └─local-fs.target @4.324s └─boot.mount @4.286s +31ms └─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.service @4.092s +149ms └─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4.092s |
29. 获取某个服务(httpd)的依赖性列表
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# systemctl list-dependencies httpd.service httpd.service ├─system.slice └─basic.target ├─firewalld.service ├─microcode.service ├─rhel-autorelabel-mark.service ├─rhel-autorelabel.service ├─rhel-configure.service ├─rhel-dmesg.service ├─rhel-loadmodules.service ├─paths.target ├─slices.target │ ├─-.slice │ └─system.slice ├─sockets.target │ ├─dbus.socket .... |
30. 按等级列出控制组
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# systemd-cgls ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 23 ├─user.slice │ └─user-0.slice │ └─session-1.scope │ ├─2498 sshd: root@pts/0 │ ├─2500 -bash │ ├─4521 systemd-cgls │ └─4522 systemd-cgls └─system.slice ├─httpd.service │ ├─4440 /usr/sbin/httpd -DFOREGROUND │ ├─4442 /usr/sbin/httpd -DFOREGROUND │ ├─4443 /usr/sbin/httpd -DFOREGROUND │ ├─4444 /usr/sbin/httpd -DFOREGROUND │ ├─4445 /usr/sbin/httpd -DFOREGROUND │ └─4446 /usr/sbin/httpd -DFOREGROUND ├─polkit.service │ └─721 /usr/lib/polkit-1/polkitd --no-debug .... |
31. 按CPU、内存、输入和输出列出控制组
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# systemd-cgtop Path Tasks %CPU Memory Input/s Output/s / 83 1.0 437.8M - - /system.slice - 0.1 - - - /system.slice/mariadb.service 2 0.1 - - - /system.slice/tuned.service 1 0.0 - - - /system.slice/httpd.service 6 0.0 - - - /system.slice/NetworkManager.service 1 - - - - /system.slice/atop.service 1 - - - - /system.slice/atopacct.service 1 - - - - /system.slice/auditd.service 1 - - - - /system.slice/crond.service 1 - - - - /system.slice/dbus.service 1 - - - - /system.slice/firewalld.service 1 - - - - /system.slice/lvm2-lvmetad.service 1 - - - - /system.slice/polkit.service 1 - - - - /system.slice/postfix.service 3 - - - - /system.slice/rsyslog.service 1 - - - - /system.slice/system-getty.slice/getty@tty1.service 1 - - - - /system.slice/systemd-journald.service 1 - - - - /system.slice/systemd-logind.service 1 - - - - /system.slice/systemd-udevd.service 1 - - - - /system.slice/webmin.service 1 - - - - /user.slice/user-0.slice/session-1.scope 3 - - - - |
控制系统运行等级
32. 启动系统救援模式
|
0 1 2 |
# systemctl rescue Broadcast message from root@tecmint on pts/0 (Wed 2015-04-29 11:31:18 IST): The system is going down to rescue mode NOW! |
33. 进入紧急模式
|
0 1 2 3 |
# systemctl emergency Welcome to emergency mode! After logging in, type "journalctl -xb" to view system logs, "systemctl reboot" to reboot, "systemctl default" to try again to boot into default mode. |
34. 列出当前使用的运行等级
|
0 1 |
# systemctl get-default multi-user.target |
35. 启动运行等级5,即图形模式
|
0 1 2 |
# systemctl isolate runlevel5.target 或 # systemctl isolate graphical.target |
36. 启动运行等级3,即多用户模式(命令行)
|
0 1 2 |
# systemctl isolate runlevel3.target 或 # systemctl isolate multiuser.target |
36. 设置多用户模式或图形模式为默认运行等级
|
0 1 |
# systemctl set-default runlevel3.target # systemctl set-default runlevel5.target |
37. 重启、停止、挂起、休眠系统或使系统进入混合睡眠
|
0 1 2 3 4 |
# systemctl reboot # systemctl halt # systemctl suspend # systemctl hibernate # systemctl hybrid-sleep |
对于不知运行等级为何物的人,说明如下。
Runlevel 0 : 关闭系统
Runlevel 1 : 救援?维护模式
Runlevel 3 : 多用户,无图形系统
Runlevel 4 : 多用户,无图形系统
Runlevel 5 : 多用户,图形化系统
Runlevel 6 : 关闭并重启机器
Linux 系统日志
许多有价值的日志文件都是由 Linux 自动地为你创建的。你可以在 /var/log 目录中找到它们。下面是在一个典型的 Ubuntu 系统中这个目录的样子:
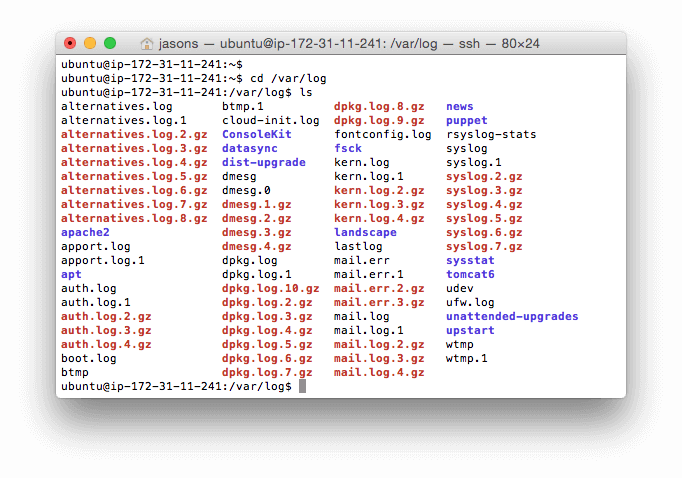
一些最为重要的 Linux 系统日志包括:
/var/log/syslog 或 /var/log/messages 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 /var/log/syslog 中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 /var/log/messages 中存储它们。
/var/log/auth.log 或 /var/log/secure 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 /var/log/auth.log 中存储认证信息,而 RedHat 和 CentOS 则在 /var/log/secure 中存储该信息。
/var/log/kern 存储内核的错误和警告数据,这对于排除与定制内核相关的故障尤为实用。
/var/log/cron 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
Digital Ocean 有一个关于这些文件的完整教程,介绍了 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们。
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
什么是 Syslog?
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog 套接字 /dev/log 上监听日志信息,然后将它们写入适当的日志文件中。
单词“syslog” 代表几个意思,并经常被用来简称如下的几个名称之一:
Syslog 守护进程 — 一个用来接收、处理和发送 syslog 信息的程序。它可以远程发送 syslog 到一个集中式的服务器或写入到一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说“发送到 syslog”。
Syslog 协议 — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 RFC-5424 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说“通过 syslog 传送”。
Syslog 信息 — syslog 格式的日志信息或事件,它包括一个带有几个标准字段的消息头。在这种使用方式中,人们常说“发送 syslog”。
Syslog 信息或事件包括一个带有几个标准字段的消息头,可以使分析和路由更方便。它们包括时间戳、应用程序的名称、在系统中信息来源的分类或位置、以及事件的优先级。
下面展示的是一个包含 syslog 消息头的日志信息,它来自于控制着到该系统的远程登录的 sshd 守护进程,这个信息描述的是一次失败的登录尝试:
|
0 |
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2 |
Syslog 格式和字段
每条 syslog 信息包含一个带有字段的信息头,这些字段是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的字段的名称上。
|
0 |
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n |
下面,你将看到一些在查找或排错时最常使用的 syslog 字段:
时间戳
时间戳 (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
2003-10-11 年,月,日。
T 为时间戳的必需元素,它将日期和时间分隔开。
22:14:15.003 是 24 小时制的时间,包括进入下一秒的毫秒数(003)。
Z 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间。
主机名
主机名 字段(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
应用名
应用名 字段(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
优先级
优先级字段或缩写为 pri (在上面的例子中对应 ) 告诉我们这个事件有多紧急或多严峻。它由两个数字字段组成:设备字段和紧急性字段。紧急性字段从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备字段描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备字段的值乘以 8,再加上紧急性字段的值:(设备字段)(8) + (紧急性字段)。第二种是 pri 文本,将以“设备字段.紧急性字段” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
在 Linux 中使用日志来排错
登录失败原因
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由插入式验证模块(PAM)来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
失败的例子:
|
0 1 2 3 |
pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2 Failed password for invalid user hoover from 10.0.2.2 port 4791 ssh2 pam_unix(sshd:auth): check pass; user unknown PAM service(sshd) ignoring max retries; 6 > 3 |
成功的例子:
|
0 1 2 |
Accepted password for hoover from 10.0.2.2 port 4792 ssh2 pam_unix(sshd:session): session opened for user hoover by (uid=0) pam_unix(sshd:session): session closed for user hoover |
你可以使用 grep 来查找哪些用户失败登录的次数最多。这些都是潜在的攻击者正在尝试和访问失败的账户。这是一个在 ubuntu 系统上的例子。
|
0 1 2 3 4 5 |
$ grep "invalid user" /var/log/auth.log | cut -d ' ' -f 10 | sort | uniq -c | sort -nr 23 oracle 18 postgres 17 nagios 10 zabbix 6 test |
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。

日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。

重启的原因
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
关机命令
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
0 1 2 |
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0) Mar 19 18:37:09 ip-172-31-11-231 sudo: ubuntu : TTY=pts/1 ; PWD=/home/ubuntu ; USER=root ; COMMAND=/sbin/shutdown -r now |
内核初始化
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
|
0 1 2 |
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Linux version 3.8.0-44-generic (buildd@tipua) (gcc version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5) ) #66~precise1-Ubuntu SMP Tue Jul 15 04:01:04 UTC 2014 (Ubuntu 3.8.0-44.66~precise1-generic 3.8.13.25) |
检测内存问题
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
例如:
|
0 1 |
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child [29923450.995084] select 5230 (docker), adj 0, size 708, to kill |
你可以使用像 grep 这样的工具找到这些日志。这个例子是在 ubuntu 中:
|
0 1 |
$ grep “Out of memory” /var/log/syslog [33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child |
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
定时任务错误日志
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
|
0 1 2 3 |
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover> Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110> Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active) Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp) |
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
它创建的日志条目:
|
0 1 |
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron) Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World! |
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
原文出处:http://www.jb51.net/LINUXjishu/378593.html
在Linux环境下,如果直接使用VI/VIM命令编辑没有修改权限的文件时,保存的时候就会提示用户无法进行保存操作,一般的解决方法只能是关闭文件重新以sudo权限打开该文件编辑后再保存(前提是用户具有sudo权限)。其实,在VI/VIM模式下通过一些简单的命令,就能在不关闭当前文件的情况下达到保存文件的目的(感谢晓哲老师提供的方法):
输入命令:%! sudo tee % > /dev/null
按提示输入sudo权限密码
输入“L”(Load File)
输入:q命令退出
关于“%! sudo tee % > /dev/null”这条命令的说明如下:
% #VI/VIM编辑的文件内容
! #管道
sudo #以root权限操作
tee #将标准输入(即通过管道过来的当前编辑的文件内容)输出到标准输出,同时写入到指定的文件中(即VI/VIM当前编辑的文件)
% #VI/VIM编辑的文件
> /dev/null #将标准输出重定向到/dev/null(不输出显示)
w3m 安装
在终端输入“w3m”,之后按提示进行安装,基本是傻瓜式的。
或者输入 sudo apt-get install w3m
之后会提示输入当前成员密码,即可进行下载安装。
PS:如果您的终端不显示中文请。安装zhcon
输入 sudo apt-get install zhcon -y
w3m 使用总结
w3m是个开放源代码的命令行下面的网页浏览器。一般的linux系统都会自带这个工具,可以通过它在命令行下面浏览网页。本文介绍这个工具的使用方法。
[功能]
w3m是个开放源代码的命令行下面的网页浏览器。 它支持表格、框架、SSL连线、颜色。如果是在适当的terminal上,甚至还支持“inline image”。 这个软件通常尽量呈现出网页本来的编排。
*常用交互式命令:
下面列出启动w3m之后常用的交互命令,更多命令参见帮助。
1)光标移动
SPC,C-v 向下翻页
b,ESC v 向上翻页
l,C-f 焦点向右
h,C-b 焦点向左
j,C-n 焦点向下
k,C-p 焦点向上
J 向上滚动一行
K 向下滚动一行
^,C-a 到行首
$,C-e 到行尾
w 到下一个单词
W 到上一个单词
> 右移一屏
< 左移一屏
. 屏幕右移一列
, 屏幕左移一列
g,M-< 到首行
G,M-> 到末行
ESC g 到指定行
Z 当前行居中
z 当前列居中
TAB 转到下个超链接
C-u,ESC TAB 到上个超链接
[ 到第一个超链接
] 到最后一个超链接
2)超链接操作
RET 打开超链接
a, ESC RET 链接另存为
u 查看链接url
i 查看图片url
I 查看图片
ESC I 图片另存为
: 标记rul字符串为锚点
ESC : 标记ID串为锚点
c 查看当前页面的URL
= 显示当前页面属性
C-g 查看当前行号
C-h 查看历史记录
F 提交表单
M 用外部浏览器打开当前页面 (use 2M and 3M to invoke second and third browser)
ESC M 用外部浏览器打开链接 (use 2ESC M and 3ESC M to invoke second and third browser)
3)文件/流 操作
U 打开URL
V 打开文件
@ 执行外部命令并导入
# 执行外部命令并浏览
4)缓存操作
B 返回
v 查看源代码
s 选择缓存
E 编辑缓存代码
C-l 重画屏幕
R 刷新
S 页面另存为
ESC s 源码另存为
ESC e 编辑图片
缓存择模式(也就是了s以后)
k, C-p 上一缓存
j, C-n 下一缓存
D 删除当前缓存
RET 转至选择的缓存
5)书签操作
ESC b 打开书签
ESC a 添加当前页到书签
6)搜索
/,C-s 向前搜索
?,C-r 向后搜索
n 下一个
N 上一个
C-w 打开/关闭 循环搜索
7)标记
C-SPC 设定/取消 标记(这个键一般被输入法占用了)
ESC p 转至上一标记
ESC n 转至下一标记
” 使用正则表达式标记
8)杂项
! 执行外部命令
H 帮助
o 设置选项
C-k 显示接受到的cookie
C-c 停止
C-z 挂起(退出)
q 退出(需确认)
Q 退出而不确认
9)行编辑模式
也就是输入”U”之后,开始输入url时候的状态。
C-f 光标向后
C-b 光标向前
C-h 删除前一字符
C-d 删除当前字符
C-k 删除光标后所有内容
C-u 删除光标前所有内容
C-a 光标到行首
C-e 光标到行尾
C-p 取得历史记录中的前一个词
C-n 取得历史记录中的后一个词
TAB,SPC 自动完成文件名
RETURN 确定
[举例]
*以网址启动w3m
$w3m mrdede.com
这样打开w3m,并且以网页打开。(如果提示不能浏览框架,试试提示中的链接) ,注意,如果机器需要代理上网,那么应该设置一个变量:http_proxy ,设置的方法: “export http_proxy=http://user:password@ip.com”.这里,user就是用户名,password就是该用户的密码,ip就是代理服务器的ip地址.
*支持简体中文的启动:
$w3m http://mrdede.com -o display_charset=GB2312
这里,时候网页无法显示中文,那么可以尝试用这种方法启动。
**进入w3m之后的操作
这里简单介绍浏览网页时候常用的一些操作,如果想要知道更多的操作,请查看交互状态下,”H”命令之后显示的帮助信息。
*显示帮助信息:
输入”H”.
*返回上次页面:
输入”B”.
这里包括帮助页面,上次的网址等等。
*查看历史url:
输入”[Ctrl]h”.
这样会查看你访问过的页面,输入B可以返回。
*输入指定网址:
输入”U”.
这是在启动w3m之后进行的,输入之后,可以在底部输入你想要访问的网址。
*屏幕上一页:
输入”b”.
*屏幕下一页:
输入”[空格]“.
*添加书签:
输入”[Esc]a”.
*列出书签:
输入”[Esc]b”.
*建立新的标签:
输入”T”.
这样会新开一个标签,内容和当前的网页一样。
*在新的标签中打开链接:
输入”[Ctrl]t”.
这里,需要先停在相应的链接上面。会新开一个标签,并且在其中显示对应的网页,适合想要同时显示多个网页的情况。
*切换到上一个标签:
输入”{“.
*切换到下一个标签:
输入”}”.
*弹出标签选择菜单:
输入”[Esc]t”.
这样会弹出一个菜单,然后可以选择你想要进入的标签。
*关闭当前标签:
输入”[Ctrl]q”.
这样会关闭当前标签。
*弹出链接列表菜单:
输入”[Esc]m”.
或”[Esc]l”.
这样显示出当前页面所链接列表,可以择相应链接并且进入。
*退出弹出菜单:
输入”h”.
或”[Ctrl]h”.
或”[Left]“.
*显示当前行:
输入”[Ctrl]g”.
*去指定行:
输入”[Esc]g”.
这样,之后输入行号将会跳到指定的行号。
*连同光标向下滚动:
输入”J”.
*连同光标向上滚动:
输入”K”.
*光标向上移动:
输入”k”.
或输入”[上箭头]“.
这里,方向移动的指令和vim编辑器中的一样,如果上下超过了页面边缘,那么会自动滚动半页使光标的所在行位于屏幕中央。
*光标向下移动:
输入”j”.
或输入”[下箭头]“.
这里,方向移动的指令和vim编辑器中的一样,如果上下超过了页面边缘,那么会自动滚动半页使光标的所在行位于屏幕中央。
*光标向左移动:
输入”h”.
或输入”[左箭头]“.
这里,方向移动的指令和vim编辑器中的一样。
*光标向右移动:
输入”l”.
或输入”[右箭头]“.
这里,方向移动的指令和vim编辑器中的一样。
*退出w3m:
输入”q”.
*切换是否接受鼠标动作:
输入”m”.
这样切换w3m是否接受鼠标动作。如果不接受鼠标动作,在X系统下面可以用鼠标选择文本,否则接受鼠标的话就无法选择文本但是能够用鼠标点击链接并打开。
*搜索字符串
输入”/<你要搜索的字符串>” .
这里,和vi上面的一样。
PS:具体的命令,可以输入’H',看帮助。
新装LINUX系统如何获得ROOT权限,图文教程
一、进入terminal
二、然后,输入sudo passwd root 并,设置密码
提示要你输入两次密码,自己设定密码,一定要记住,然后切换到root使用

三、输入 su root
要求你输入密码,然后,输入刚才设定的密码OK,进去了
如果不想切换root但是想拥有大部分root权限
可以在使用命令时候加上sudo,
sudo mount挂载
sudo命令
another
如果你想再linux上切换用户,输入,su + 用户名
就OK了,他会要求你输入密码