mysql索引类型
mysql索引类型normal,unique,full text的区别是什么?
normal:表示普通索引
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
MySQL 索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
普通索引
创建索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
|
0 |
CREATE INDEX indexName ON mytable(username(length)); |
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引)
|
0 |
ALTER mytable ADD INDEX [indexName] ON (username(length)) |
|
0 1 2 3 4 5 6 7 8 |
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); |
|
0 |
DROP INDEX [indexName] ON mytable; |
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
创建索引
|
0 |
CREATE UNIQUE INDEX indexName ON mytable(username(length)) |
|
0 |
ALTER table mytable ADD UNIQUE [indexName] (username(length)) |
|
0 1 2 3 4 5 6 7 8 |
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) ); |
使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:
- ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
- ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
- ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
- ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
以下实例为在表中添加索引。
|
0 |
mysql> ALTER TABLE testalter_tbl ADD INDEX (c); |
你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引:
|
0 |
mysql> ALTER TABLE testalter_tbl DROP INDEX c; |
使用 ALTER 命令添加和删除主键
主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下:
|
0 1 |
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i); |
你也可以使用 ALTER 命令删除主键:
|
0 |
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY; |
删除指定时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。
显示索引信息
你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。可以通过添加 \G 来格式化输出信息。
尝试以下实例:
|
0 1 |
mysql> SHOW INDEX FROM table_name; \G ........ |
mysql索引方法
在mysql中常用两种索引算法BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:
select * from user where name like 'jack%';
select * from user where name like 'jac%k%';
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like '%jack';
select * from user where name like simply_name;
二、Hash
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
1. Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。
2. 联合索引中,Hash索引不能利用部分索引键查询。
对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
3. Hash索引无法避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
4. Hash索引任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
5. Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
补充:
<=>,这个符号于“=”一致,在数学中这个符号叫“等价于”,代表”推理中左边可以推出右边,右边也可推出左边”的意思。P=>Q:若P则Q,P<=Q:若Q则P,P<=>Q:若P则Q且若Q则P)。接下来看一下我的测试,在库中建一张test表,建一个hash索引num1_hash:
|
0 1 2 3 4 5 6 7 |
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `num1` int(11) DEFAULT NULL, `num2` int(11) DEFAULT NULL, `num3` decimal(14,2) DEFAULT NULL, PRIMARY KEY (`id`), KEY `num1_hash` (`num1`) USING HASH ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; |
初始化几条数据在里面:
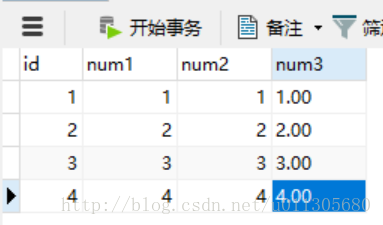
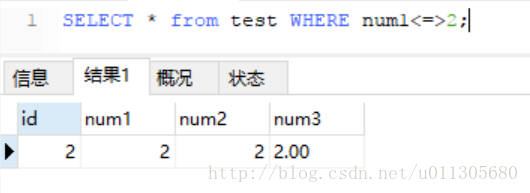
使用<=>符号查询,结果如下:
接下来再看看hash索引对<,<=,>,>=符号是否支持:

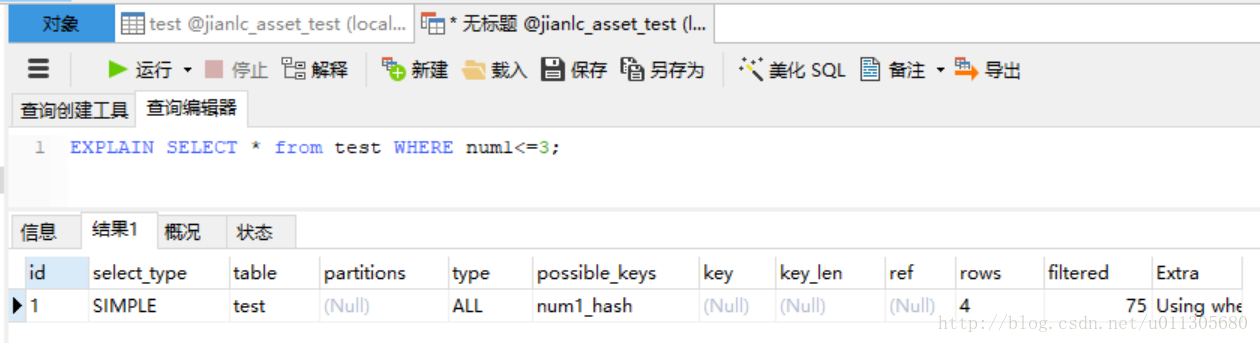


可以看出在<=2与<3是能命中索引的,在<=3与<4是全表扫描,所以<,>等符号也不是完全不能命中索引,跟btree测试结果一样,但是对查询的优化有没有用还没有研究过,后续会继续研究一下进行补充。