开始。这是最容易令人丧失斗志的两个字。迈出第一步通常最艰难。当可以选择的方向太多时,就更让人两腿发软了。
从哪里开始?
本文旨在通过七个步骤,使用全部免费的线上资料,帮助新人获取最基本的 Python 机器学习知识,直至成为博学的机器学习实践者。这篇概述的主要目的是带领读者接触众多免费的学习资源。这些资源有很多,但哪些是最好的?哪些相互补充?怎样的学习顺序才最好?
我假定本文的读者不是以下任何领域的专家:
▪ 机器学习
▪ Python
▪ 任何 Python 的机器学习、科学计算、数据分析库
如果你有前两个领域其一或全部的基础知识,可能会很有帮助,但这些也不是必需的。在下面几个步骤中的前几项多花点时间就可以弥补。
第一步:基本 Python 技能
如果要使用 Python 进行机器学习,拥有对 Python 有基础的理解非常关键。幸运的是,Python 是当前普遍使用的流行语言,并纳入了科学计算和机器学习的内容,所以找到入门教程并不困难。在选择起点时,很大程度上要取决于你之前的 Python 经验和编程经验。
首先要安装 Python 。由于我们要使用机器学习和科学计算的 packages ,这里建议安装 Anaconda。Anaconda 是一个可在 Linux , OSX , Windows 上运行的 Python 实现工具,拥有所需的机器学习 packages ,包括 numpy,scikit-learn,matplotlib。它还包含iPython Notebook ,一个带有许多教程的交互式环境。这里推荐使用 Python 2.7 ,不是因为特殊原因,只是因为它是目前安装版本中的主流。

如果你之前没有编程知识,建议你阅读这本免费电子书,然后再接触其他学习材料:
▪ Python The Hard Way 作者Zed A. Shaw
如果你之前有编程知识,但不是Python的,又或者你的Python水平很基础,推荐下列一种或几种教程:
▪ Google Developers Python Course((强烈推荐给视觉型学习者)
▪ An Introduction to Python for Scientific Computing (from UCSB Engineering) 作者 M. Scott Shell (一个很好的 Python 科学计算简介,60 页)
对于想要速成课程的人,这里有:
▪ Learn X in Y Minutes (X = Python)
当然,如果你是个经验丰富的 Python 程序员,可以跳过这一步。尽管如此,还是建议你把通俗易懂的 Python documentation 放在手边。
第二步:机器学习基础技能
KDnuggets 的 Zachary Lipton 指出,人们对于“数据科学家”的认知千差万别。这实际上是对机器学习领域的反映。数据科学家在不同程度上使用计算学习算法。要建立和使用支持向量机模型,熟知核函数方法是否是必需的?答案当然不是。就像现实生活中的许多事情一样,所需要的理论深入程度与具体的实际应用有关。获取对机器学习算法的深入理解不是本文的讨论范围, 而且这通常需要在学术领域投入大量时间,或者至少要通过密集的自学才能达到。
好消息是,你不必拥有博士级别的机器学习理论能力才能进行实践,就如同不是所有程序员都必须接受计算机理论教育才能写好代码。
吴恩达在 Coursera 的课程饱受赞誉。但我的建议是去看看一名以前的学生做的笔记。略过那些针对 Octave(一个与 Python 无关的,类 Matlab 语言)的内容。需要注意,这些不是“官方”的笔记,虽然看起来的确抓住了吴恩达课程材料的相关内容。如果你有时间,可以自己去 Coursera 完成这个课程 :Andrew Ng’s Machine Learning course 。
除了吴恩达的课程以外,还有很多其他视频教程。我是 Tom Mitchell 的粉丝,下面是他(与Maria-Florina Balcan 共同完成的)最新的课程视频,对学习者非常友好:
▪ Tom Mitchell Machine Learning Lectures
你不需要现在看完全部的笔记和视频。比较好的策略是向前推进,去做下面的练习,需要的时候再查阅笔记和视频。比如,你要做一个回归模型,就可以去查阅吴恩达课程有关回归的笔记以及/或者 Mitchell 的视频。
第三步:科学计算 Python packages 一览
好了。现在我们有了 Python 编程经验,并对机器学习有所了解。Python 有很多为机器学习提供便利的开源库。通常它们被称为 Python 科学库(scientific Python libraries),用以执行基本的数据科学任务(这里有一点程度主观色彩):
▪ numpy – 主要用于 N 维数组
▪ pandas – Python 数据分析库,包含 dataframe 等结构
▪ matplotlib – 2D 绘图库,产出质量足以进行印刷的图
▪ scikit-learn – 数据分析、数据挖掘任务使用的机器学习算法
学习以上这些内容可以使用:
▪ Scipy Lecture Notes 作者 Gaël Varoquaux, Emmanuelle Gouillart, Olav Vahtras
下面这个 pandas 教程也不错,贴近主题:
在后面的教程中你会看到其他一些 packages ,比如包括 Seaborn ,一个基于 matplotlib 的可视化库。前面提到的 packages (再次承认具有一定主观色彩)是许多 Python 机器学习任务的核心工具。不过,理解它们也可以让你在之后的教程中更好理解其他相关 packages。
好了,现在到了有意思的部分…..
第四步:开始用 Python 进行机器学习
Python。搞定。
机器学习基础。搞定。
Numpy。搞定。
Pandas。搞定。
Matplotlib。搞定。
是时候用 Python 的标准机器学习库,scikit-learn,实现机器学习算法了。
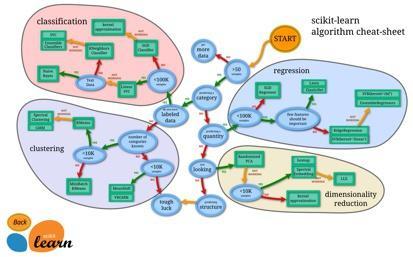
scikit-learn 算法选择图
下面许多教程和练习都基于交互式环境 iPython (Jupyter) Notebook 。这些 iPython Notebooks有些可以在网上观看,有些可以下载到本地电脑。
▪ iPython Notebook 概览 斯坦福大学
也请注意下面的资源来自网络。所有资源属于作者。如果出于某种原因,你发现有作者没有被提及,请告知我,我会尽快改正。在此特别要向 Jake VanderPlas,Randal Olson,Donne Martin,Kevin Markham,Colin Raffel 致敬,感谢他们提供的优秀免费资源。
下面是 scikit-learn 的入门教程。在进行下一个步骤之前,推荐做完下列全部教程。
对于 scikit-learn 的整体介绍,它是 Python 最常用的通用机器学习库,包含knn最近邻算法:
▪ An Introduction to scikit-learn 作者 Jake VanderPlas
更深入更宽泛的介绍,包含一个新手项目,从头到尾使用一个著名的数据集:
▪ Example Machine Learning Notebook 作者 Randal Olson
专注于 scikit-learn 中评估不同模型的策略,涉及训练集/测试集拆分:
▪ Model Evaluation 作者 Kevin Markham
第五步:Python 机器学习主题
在 scikit-learn 打下基础以后,我们可以探索更多有用的常见算法。让我们从最知名的机器学习算法之一,k-means 聚类开始。对于无监督学习问题,k-means 通常简单有效:
▪ k-means Clustering 作者 Jake VanderPlas
接下来是分类,让我们看看史上最流行的分类方法之一,决策树:
▪ Decision Trees via The Grimm Scientist
分类之后,是连续数字变量的预测:
▪ Linear Regression 作者 Jake VanderPlas
通过逻辑斯蒂回归,我们可以用回归解决分类问题:
▪ Logistic Regression 作者 Kevin Markham
第六步:Python高级机器学习
接触过 scikit-learn,现在让我们把注意力转向更高级的内容。首先是支持向量机,一个无需线性的分类器,它依赖复杂的数据转换,把数据投向高维空间。
▪ Support Vector Machines 作者 Jake VanderPlas
接下来是随机森林,一种集成分类器。下面的教程通过 Kaggle Titanic Competition讲解。
▪ Kaggle Titanic Competition (with Random Forests) 作者 Donne Martin
降维是一种减少问题涉及的变量数目的方法。PCA 主成分分析是一种无监督学习降维的特殊形式:
▪ Dimensionality Reduction 作者 Jake VanderPlas
在开始下一步之前,可以暂停一下,回想我们在短短的时间已经走了多远。
通过使用 Python 和它的机器学习库,我们涵盖了一些最常用最知名的机器学习算法( knn 最近邻,k-means 聚类,支持向量机),了解了一种强有力的集成方法(随机森林),涉及了一些其他机器学习支持方案(降维,模型验证技巧)。在一些基础机器学习的技巧的帮助下,我们开始有了一个渐渐丰富的工具箱。
在结束以前,让我们给工具箱增加一个需求很大的工具:
第七步 :Python 深度学习
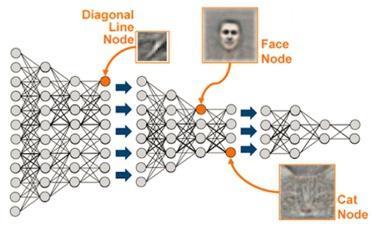
学习,深深地。
到处都在深度学习!深度学习基于过去几十年的神经网络研究,但最近几年的发展大大增加了深度神经网络的能力和对于它的兴趣。如果你不熟悉深度学习,KDnuggets 有许多文章,详细介绍最近的进展、成果,以及对这项技术的赞誉。
本文的最后一部分并不想成为某种深度学习示范教程。我们会关注基于两个Python深度学习库的简单应用。对于想了解更多的读者,我推荐下面这本免费在线书:
▪ Neural Networks and Deep Learning 作者 Michael Nielsen
Theano是我们关注的第一个 Python 深度学习库。根据作者所说:
作为一个 Python 库,Theano 让你可以有效定义、优化、评估包含多维数组的数学表达式。
下面的 Theano 深度学习教程很长,但非常不错,描述详细,有大量评论:
▪ Theano Deep Learning Tutorial 作者 Colin Raffel
我们关注的另一个库是 Caffe。根据它的作者所说:
Caffe 是一个深度学习框架。开发过程中时刻考虑着表达式、速度、模型。 它是由 Berkeley Vision and Learning Center (BVLC) 和社区贡献者共同开发的。
这个教程是本文的压轴。尽管上面列举了一些有趣的案例,没有那个比得上下面这个:用 Caffe 实现 Google 的 #DeepDream。希望你喜欢!理解这个教程以后,尽情玩乐,让你的处理器开始自己做梦吧。
▪ Dreaming Deep with Caffe via Google’s GitHub
我不敢保证Python机器学习是速成的或简单的。但只要投入时间,遵循这七个步骤,你无疑会对于这个领域拥有足够的熟练度和理解,会使用流行的 Python 库实现许多机器学习算法,甚至当今深度学习领域的前沿内容。